当新页面迟迟不被百度抓取时,最直接、最稳定的办法之一,就是使用百度推送接口主动提交 URL。
它的作用并不是“秒收录”,而是明确告诉百度:这个页面存在,可以来抓。
如果你还不清楚抓取、收录、索引、排名之间的区别,可以先看这篇:
抓取、收录、索引、排名到底有什么区别?
下面这篇内容,我会用最简单的方式,把推送接口格式、推送逻辑,以及一个可直接使用的工具一次讲清楚。
百度推送接口格式(官方接口说明)
百度提供了标准的 URL 推送接口,通过 HTTP POST 的方式提交单条或多条 URL。
http://data.zz.baidu.com/urls?site=你的域名&token=你的token
site:不带协议的域名(example.com)token:百度站长平台里生成的推送 Token
Python 示例代码
下面这段 Python 示例代码实现了三个核心功能:
- 每次只推送 1 条 URL,避免一次性耗尽额度
- 已推送 URL 写入日志,下次不会重复提交
- 检测推送额度用尽后,自动停止程序
import requests
import time
import os
import sys
import json
SITE = "www.你的域名"
TOKEN = "你的token"
API = f"http://data.zz.baidu.com/urls?site={SITE}&token={TOKEN}"
HEADERS = {"Content-Type": "text/plain"}
URL_FILE = "url.txt"
PUSHED_LOG = "pushed.log"
FAILED_LOG = "failed.log"
def read_lines(file_path):
if not os.path.exists(file_path):
return []
with open(file_path, "r", encoding="utf-8") as f:
return [line.strip() for line in f if line.strip()]
def append_line(file_path, text):
with open(file_path, "a", encoding="utf-8") as f:
f.write(text + "\n")
def push_one_url(url):
resp = requests.post(
API,
data=url,
headers=HEADERS,
timeout=10
)
return resp.status_code, resp.text
def is_quota_exceeded(resp_text):
"""
判断百度推送额度是否已用完
"""
try:
data = json.loads(resp_text)
if data.get("error") in (400, 429):
return True
if "quota" in str(data.get("message", "")).lower():
return True
except json.JSONDecodeError:
pass
return False
print("▶ 百度推送任务启动")
while True:
all_urls = read_lines(URL_FILE)
pushed_urls = set(read_lines(PUSHED_LOG))
# 找一条还没推送的 URL
pending_url = None
for u in all_urls:
if u not in pushed_urls:
pending_url = u
break
if not pending_url:
print("✅ 所有 URL 已推送完成,任务结束")
break
print("→ 推送:", pending_url)
code, result = push_one_url(pending_url)
# —— 额度判断(最高优先级) ——
if is_quota_exceeded(result):
print("? 推送额度已用完,立即停止")
print("返回信息:", result)
sys.exit(0)
if code == 200 and '"success"' in result:
append_line(PUSHED_LOG, pending_url)
print("✅ 成功")
else:
append_line(FAILED_LOG, pending_url)
print("❌ 失败:", result)
time.sleep(1) # 控制推送节奏
使用方式很简单:
url.txt:每行放一个需要推送的页面 URLpushed.log:成功推送的 URL 会自动记录failed.log:推送失败的 URL 会单独保存,方便排查
程序再次运行时,会自动跳过已经成功推送的 URL,不会重复消耗额度。
工具下载(适合不想折腾 Python 环境的站长)
如果你不熟悉 Python,或者只是想快速使用推送功能,我已经把上述脚本打包成了可执行的 exe 文件。
下面是我用auto-py-to-exe打包好的exe文件,下载后可直接使用
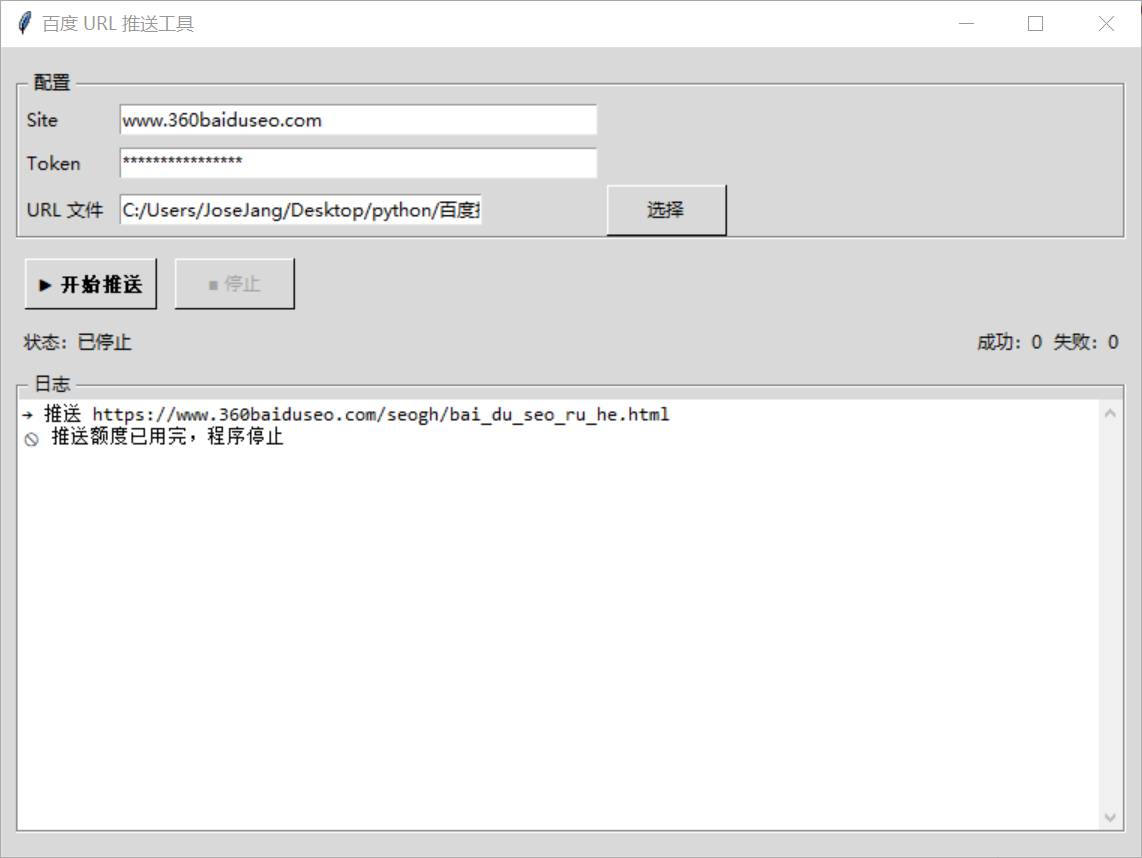
下载链接: https://url89.ctfile.com/f/63049189-8608957103-6d9803?p=9487 (访问密码: 9487)
该工具仅用于调用百度官方推送接口,不涉及任何第三方服务,也不会收集站点信息。
需要注意的是,百度推送只是抓取层面的辅助工具,并不能保证页面一定收录或排名。
是否收录,最终仍然取决于页面内容质量、站点整体信任度以及结构是否清晰。
关于百度如何从抓取 → 判断 → 建立信任,我在这篇文章里完整拆过:
搜索引擎是如何评估一个新站的?从抓取到信任的真实逻辑
推送的作用,是让百度更快“看到你”,而不是替你“通过考试”。