——搜索引擎如何一步步“认识”你的页面
很多 SEO 初学者,甚至做了几年站的人,都会把这四个词混在一起用:
“百度抓取了是不是就收录了?”
“收录了为啥搜不到?”
“索引和收录是不是一回事?”
“没排名是不是没被索引?”
这些问题的根源只有一个:
你在用“结果词”,去理解“过程系统”。
如果你想从整体视角理解搜索引擎的判断方式,可以结合
搜索引擎是如何评估一个新站的?,
以及
新站从抓取到收录,搜索引擎真实需要多久?。
一起理解,会更清楚后面的判断逻辑。
这篇文章,我们按真实搜索引擎工作顺序来拆解。
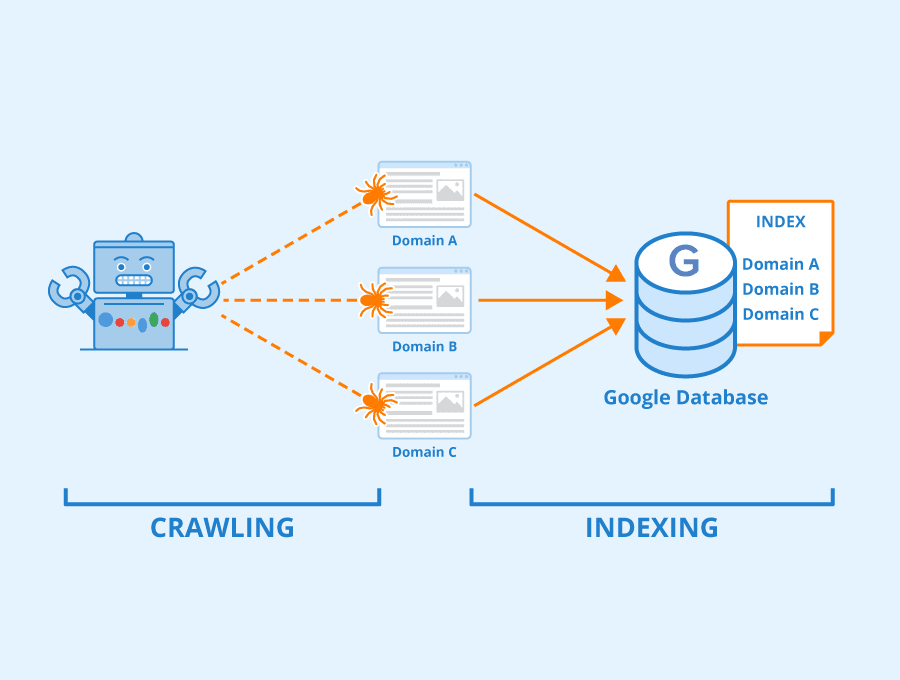
一、抓取(Crawl):搜索引擎第一次“看到你”
抓取,是搜索引擎派出爬虫(Spider / Bot),访问你网页的行为。
注意一个关键点:
? 抓取 ≠ 认可 ≠ 保存
你可以把抓取理解为:
搜索引擎只是“路过你家门口,看了一眼门牌号”。
抓取阶段只回答一个问题
“这个 URL 能不能访问?”
它关心的是:
HTTP 状态码是不是 200
页面能不能正常加载
有没有被 robots.txt / noindex 阻挡
服务器是否稳定、响应是否过慢
常见误区:
❌ 日志里看到蜘蛛 ≠ 页面有价值
❌ 抓取频繁 ≠ 马上收录
抓取只是资格检查,不是入场券。
在抓取阶段,搜索引擎通常通过链接发现页面,关于搜索引擎在抓取阶段是如何发现和获取 URL 的,可以参考搜索引擎在抓取阶段是如何发现页面的?

二、收录(Index Inclusion):被放进“候选仓库”
收录,是搜索引擎决定:
“这个页面,值得先存起来。”
注意措辞:存起来,不等于展示。
你可以理解为:
搜索引擎把页面放进一个“可能有用的仓库”,但还没决定什么时候用。
搜索引擎在这一层判断什么?
内容是否完整(不是空壳页)
是否明显重复(站内 / 站外)
页面是否具备最基础的信息价值
是否存在明显作弊特征
为什么很多页面“抓取了但没收录”?
原因往往不是技术,而是内容层级太低:
内容太短、太泛
和站内已有内容高度重合
没有清晰主题(关键词混乱)
很多人误以为:
页面一旦被收录,就等于已经能被搜索引擎正常使用。
实际上在搜索引擎内部,
收录只是“存档动作”,索引才是“理解动作”。
这中间,存在一个被大量忽略的灰色阶段:
页面被保存了,但搜索引擎还没完全确认它“是干什么的”。
? 收录,是“存档许可”,不是“曝光许可”。
如果页面长期卡在“抓取后不收录”,通常不是技术问题,而是内容判断出了偏差,
可以先从SEO 优化的方法有哪些?理解整体方向,再对照百度不收录页面的 10 个常见原因逐项排查。

三、索引(Indexing):进入可检索系统
这是90% 的人理解最混乱的一步。
索引 ≠ 收录
索引意味着:
页面内容已经被解析、拆词、结构化,进入搜索引擎的可检索数据库。
只有被索引的页面,才有资格参与搜索匹配。? 不被索引,等于搜索引擎“看不懂你”。
索引阶段,搜索引擎在做什么?
- 提取正文主题
- 分析标题、段落结构
- 建立关键词 ↔ 页面 的对应关系
- >判断页面“是讲什么的”
这里有一个很多人忽略的关键点:
搜索引擎在索引阶段,并不是简单“提取关键词”,而是在判断
这整个页面是否围绕同一个清晰主题展开。
如果页面内容看起来信息很多,但主题不断跳转、概念混杂,
搜索引擎就很难建立稳定的“主题判断”,
这类页面即使被收录,也往往进入低优先级索引区。
关于这一点,可以结合这篇文章一起理解:
你可以把索引理解为:
把一本书拆成目录、标签、关键词,放进图书馆检索系统。
为什么“site 能查到,但关键词搜不到”?
因为:
- 页面被收录,但未进入核心索引
- 或进入了低优先级索引区
- 搜索引擎对该页“主题判断不清晰”
这一步,内容结构 > 内容长度。
四、排名(Ranking):竞争开始的地方
只有到了这里,SEO 才真正开始“卷”。
排名是一个动态过程,本质是:
在某个搜索词下,谁更值得被用户看到。
排名不是绝对值,而是对比值
不同搜索引擎,对排名的判断逻辑并不一样,例如可以参考必应 SEO 和谷歌 SEO 的区别。
搜索引擎不会问:
“你这个页面好不好?”
而是问:
“在这 100 个页面里,你排第几?”
参与排名的常见因素包括:
页面主题匹配度
内容深度与完整性
内链 / 外链支持
用户行为反馈(停留、点击)
所以你会看到:
新页面 → 有时先冲一波
老页面 → 稳定但不一定第一
同一页面 → 不同词排名差异巨大

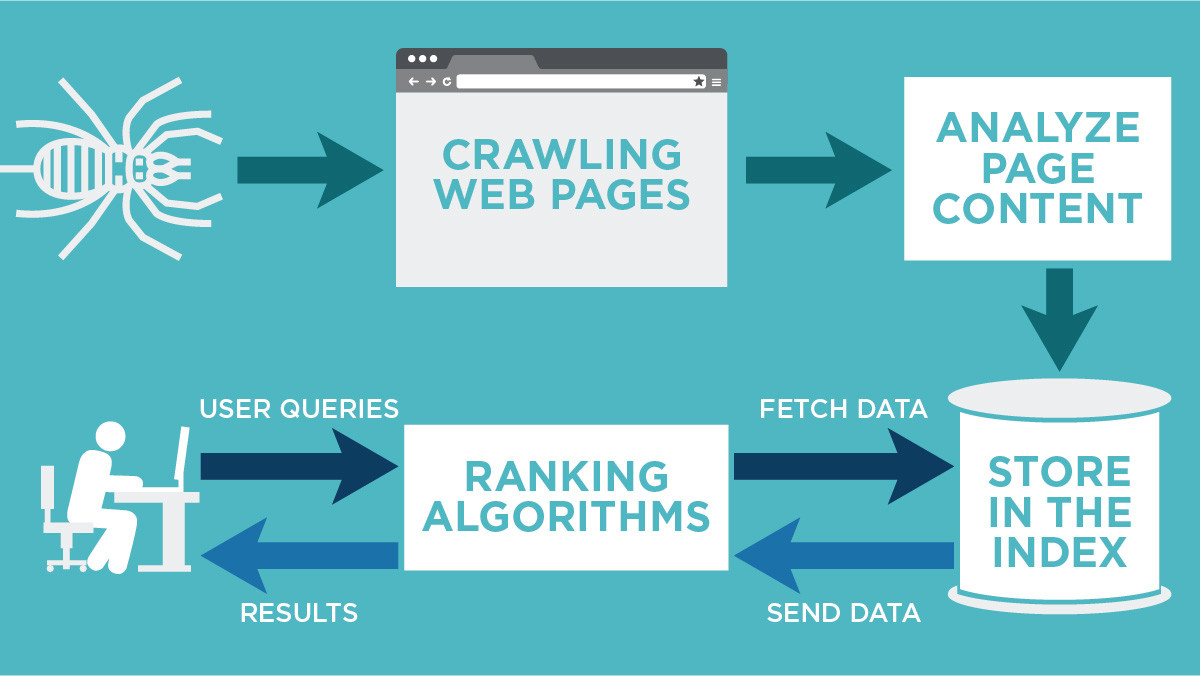
五、一张“人话版流程图”帮你彻底记住
用一句话总结四个阶段:
抓取 = 看见你
收录 = 先存着
索引 = 知道你在讲什么
排名 = 决定推不推你
任何一个环节出问题,后面全断。
六、常见错误理解纠偏
❌ “不排名就是没收录”
→ 很多页面是已索引但竞争失败❌ “疯狂提交链接能解决一切”
→ 只能解决抓取,解决不了索引判断❌ “内容越多越容易收录”
→ 搜索引擎更怕无差别堆内容
SEO 真正的核心,不是技巧,是理解判断逻辑。
七、你现在应该关注哪一步?
给你一个判断公式:
新站 / 新页面
→ 优先:抓取 → 收录已收录但搜不到
→ 问题在索引有索引但没流量
→ 问题在排名竞争
不要用“排名工具”的视角,去解决“系统流程”的问题。
八、如何快速判断一个页面卡在哪一步?
- 日志能看到蜘蛛 → 只代表抓取
- site 查得到 URL → 至少被收录
- 关键词完全搜不到 → 可能未进入核心索引
- 有展现没点击 → 排名阶段问题
? 判断清楚“页面卡在哪一步”,比盲目优化重要得多。
本文内容基于实际 SEO项目 经验整理,并由AI工具辅助梳理结构。